Artificial intelligence is rapidly transforming how machines interpret and interact with the visual world. From autonomous driving systems and retail analytics to healthcare imaging and security monitoring, computer vision has become a critical technology powering innovation across industries. However, building successful computer vision solutions requires more than advanced algorithms. The true challenge lies in preparing the massive volumes of visual data needed to train these systems.
Computer vision models depend on structured and accurately labeled datasets to understand objects, scenes, and motion within images and videos. Raw visual data alone cannot teach machines how to interpret the world around them. It must first be carefully organized, categorized, and labeled before it becomes useful for machine learning.
This is where video annotation services play a fundamental role. By converting raw video footage into structured datasets, these services enable AI models to learn patterns, detect objects, and analyze motion effectively. As organizations expand their AI initiatives, the ability to scale computer vision projects increasingly depends on reliable data preparation.
The success of modern computer vision systems is closely tied to the quality and scalability of the data that trains them.
The Growing Complexity of Computer Vision Projects
Computer vision has evolved far beyond simple image recognition tasks. Modern AI systems must analyze complex environments filled with moving objects, changing lighting conditions, and unpredictable scenarios.
For example, autonomous vehicles must interpret traffic signals, detect pedestrians, track nearby vehicles, and respond to unexpected obstacles in real time. Similarly, smart surveillance systems must monitor large areas and detect unusual behavior across thousands of video streams.
These systems require massive datasets containing annotated examples of real-world situations. Each dataset must capture diverse scenarios, object variations, and environmental conditions.
Without well-prepared training data, computer vision models cannot learn how to generalize across different environments. This limitation makes data preparation one of the most critical steps in AI development.
Large-scale computer vision projects succeed when training data reflects the complexity of real-world environments.
Why Data Annotation Is Essential for Scaling AI
Scaling an AI project means increasing its ability to handle more data, support new applications, and perform accurately across a wide range of scenarios. Achieving this level of scalability requires training datasets that grow alongside the AI system itself.
Video annotation services help organizations manage this growth by converting large volumes of raw video footage into structured training datasets. Annotators examine each frame and label objects, actions, and contextual elements that are relevant to the machine learning model.
Through this process, AI models learn how to recognize objects, track movement, and interpret interactions within dynamic scenes.
As datasets expand, models gain more exposure to different scenarios, allowing them to improve their performance and reliability.
Scalable AI development begins with scalable data preparation processes.
Transforming Raw Video Data into Structured Intelligence
Video files contain enormous amounts of information. A single minute of footage can contain thousands of frames, each filled with objects, motion, and environmental details.
For machine learning algorithms, raw video footage appears as a sequence of pixels without meaning or context. Video annotation services bridge this gap by adding labels that describe what is happening within each frame.
These annotations provide essential information such as object boundaries, object categories, and motion paths. This structured data allows AI systems to understand how objects appear, move, and interact with their surroundings.
As models analyze thousands or millions of annotated examples, they begin to identify patterns that help them interpret new visual inputs.
Turning unstructured footage into organized training data unlocks the full potential of computer vision systems.
Key Annotation Techniques Used in Large-Scale Projects
Different annotation techniques are used depending on the requirements of the AI model and the complexity of the dataset.
Bounding Boxes
Bounding boxes mark the location of objects within a frame. This technique is widely used for object detection tasks such as identifying vehicles, pedestrians, or animals.
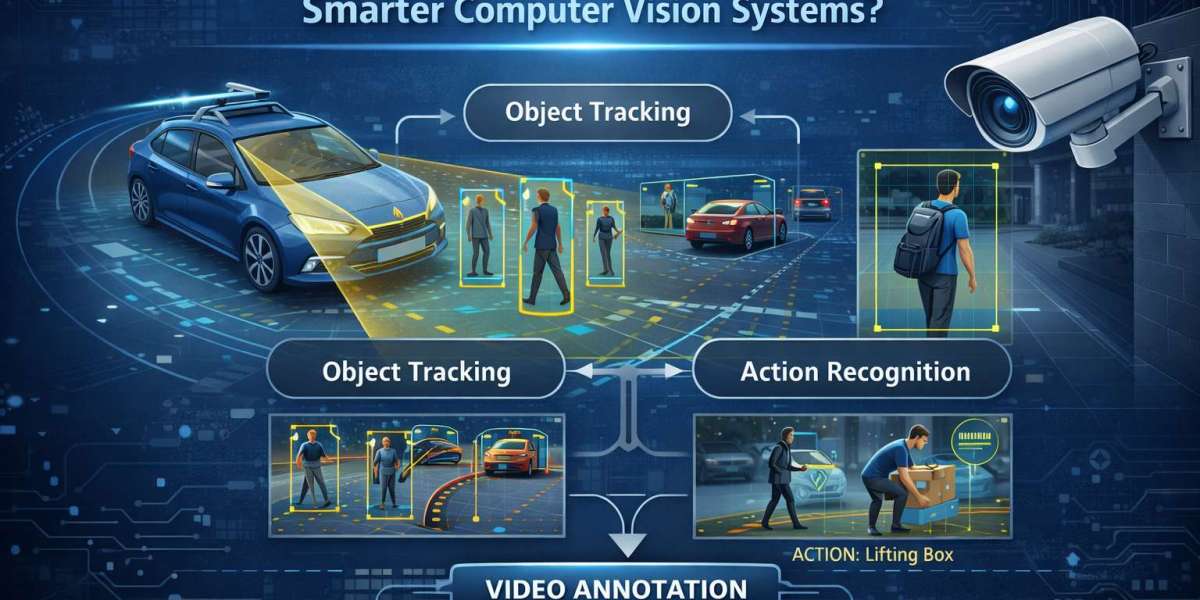
Object Tracking
Object tracking follows a labeled object across multiple frames in a video sequence. This technique allows AI models to study movement patterns and interactions over time.
Polygon Annotation
Polygon annotation outlines objects with precise boundaries. It is particularly useful for irregularly shaped objects that require detailed labeling.
Semantic Segmentation
Semantic segmentation assigns a label to every pixel within an image or video frame. This approach helps AI models understand entire environments rather than focusing on individual objects.
Keypoint Annotation
Keypoint annotation identifies specific points on objects, such as joints in the human body or key positions on machinery. This technique is often used in motion analysis and gesture recognition.
These methods collectively enable AI systems to develop a deeper understanding of complex visual scenes.
Accurate annotation techniques create the foundation for reliable computer vision models.
Industries Driving the Demand for Scalable Annotation
As AI adoption grows, many industries require large-scale annotated video datasets to train their computer vision systems.
Autonomous vehicle developers depend on massive driving datasets to teach AI how to navigate roads safely. These datasets include labeled examples of vehicles, pedestrians, road signs, and environmental conditions.
Healthcare organizations use visual datasets to develop AI tools that assist doctors in analyzing medical imaging and monitoring surgical procedures.
Retail companies analyze in-store customer behavior using computer vision systems trained on annotated surveillance footage.
Manufacturing industries apply visual inspection technologies to detect defects and monitor production lines.
Security and public safety agencies rely on AI-powered surveillance systems that detect suspicious activities in real time.
Across these industries, the demand for reliable data preparation continues to grow as organizations expand their AI capabilities.
Challenges in Scaling Annotation Workflows
Scaling computer vision projects is not without challenges. Preparing large datasets requires significant time, resources, and coordination.
One of the biggest challenges is the sheer volume of video data. Each frame must be reviewed and labeled carefully to ensure that the AI model learns accurate patterns.
Maintaining consistency across annotations is another critical challenge. When datasets are created by multiple annotators, clear guidelines and quality checks are necessary to ensure uniform labeling standards.
Environmental complexity also creates difficulties. Objects may be partially hidden, move quickly across frames, or appear under different lighting conditions.
These factors highlight why structured annotation workflows and strong quality assurance processes are essential for large-scale AI projects.
High-quality training datasets are built through careful planning, collaboration, and continuous quality verification.
Human Expertise and AI-Assisted Annotation
While automation tools have improved the efficiency of data labeling, human expertise remains essential in large annotation projects.
AI-assisted annotation platforms can automatically detect objects and suggest labels. However, human reviewers verify these suggestions to ensure accuracy and contextual understanding.
Experienced annotators can identify subtle details that automated systems might overlook, especially in complex scenes where objects interact or overlap.
Quality control teams also review datasets to confirm that annotations remain consistent throughout the entire dataset.
The combination of intelligent tools and human insight enables scalable and reliable data preparation.
Preparing for the Future of Computer Vision
As artificial intelligence continues to expand into new industries, computer vision will become even more important. Emerging technologies such as robotics, smart cities, augmented reality, and automated logistics rely heavily on AI systems that interpret visual information.
These technologies require enormous volumes of annotated video data to train their models effectively.
Organizations that invest in strong data preparation workflows will be better positioned to scale their AI initiatives and develop reliable computer vision applications.
The future of visual intelligence will depend on the ability to manage and annotate massive datasets efficiently.
Final Thoughts
Scaling computer vision projects requires more than powerful algorithms. It requires large volumes of structured, accurate training data that allows AI models to understand complex visual environments.
Video annotation services play a critical role in transforming raw video footage into meaningful datasets that machines can learn from. By labeling objects, tracking motion, and organizing visual information, annotation specialists enable AI systems to interpret real-world scenarios with greater precision.
As industries continue to adopt AI technologies, the demand for reliable and scalable data preparation will continue to grow.
Strong datasets create strong AI models, and reliable annotation processes ensure that computer vision systems can evolve, adapt, and perform accurately in the real world.
FAQs
Why is video data important for scaling computer vision projects?
Video data provides continuous sequences of frames that capture motion and context. This allows AI models to learn how objects move and interact within dynamic environments.
How do annotation processes support large AI datasets?
Annotation processes organize visual data by labeling objects and actions within each frame, enabling machine learning algorithms to recognize patterns and interpret scenes accurately.
Which industries benefit most from scalable computer vision systems?
Industries such as autonomous driving, healthcare, retail analytics, manufacturing, robotics, and public safety rely heavily on scalable computer vision technologies.
Can automated tools handle large annotation tasks?
Automation tools can assist in detecting objects and suggesting labels, but human validation is necessary to ensure accuracy and maintain high-quality datasets.
What makes a video dataset suitable for training AI models?
A high-quality dataset includes accurate labels, diverse scenarios, consistent annotation standards, and sufficient data volume to represent real-world conditions.











